Demographics
Gender
This diagram shows the rpartition of authors for all documents which match the project criterias within the filtered period by gender when it can be determined:
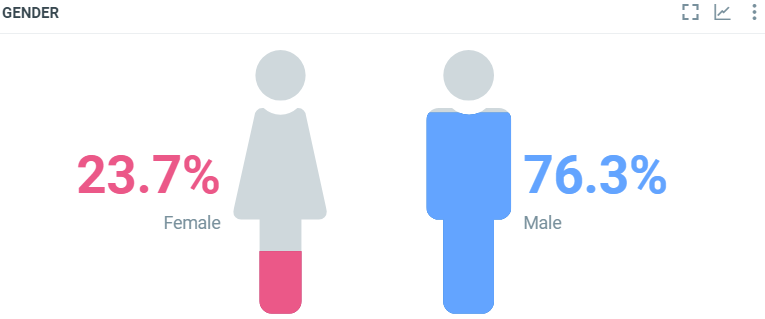
In this sample, over the filtered period (between the 1st of October and the 8th of october), we got 23.7% of the document (where the gender is known) written by women, 76.3% by men.
To retrieve this result, we can use gender histogram:
curl -L -X GET 'https://api.talkwalker.com/api/v1/search/p/<project_id>/histogram/gender?access_token=<access_token>&q=published:>1633039200000 AND published:<1633644000000'
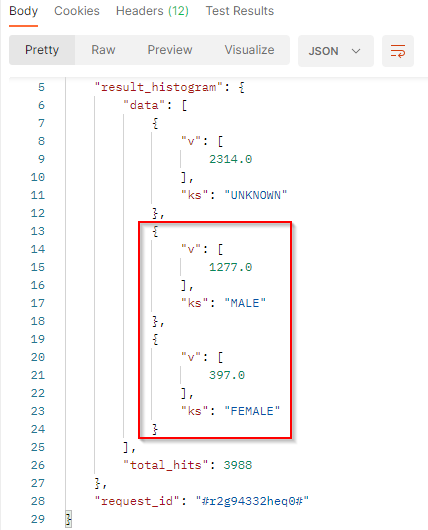
The results come with the gender UNKOWN when the gender cannot be determined.
To retrieve percentages, we should apply this formula:
Percent of women = #FEMALE / (#FEMALE + #MALE)
Percent of men = #FEMALE / (#FEMALE + #MALE)
In our sample :
vis the number of documents that match the filter criteria and the gender. 397 / (397 + 1277) = 397 / 1674 = 0.2371 = 23.7% of women.ksis the gender.total_hits: Total number of documents match the filter criteria.
Age
This diagram shows the repartition of authors for all documents which match the project criterias within the filtered period by age when it can be determined:
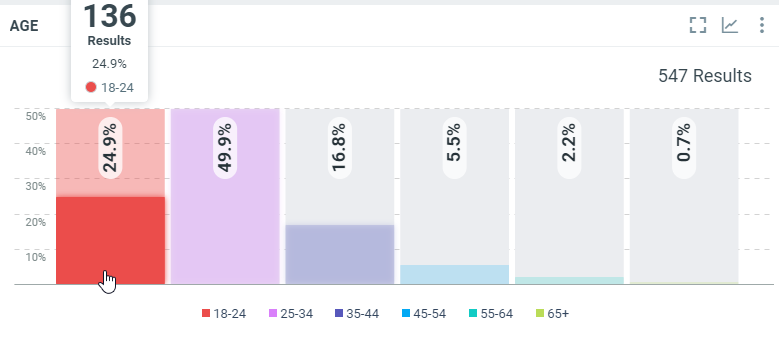
In this sample, over the filtered period (between the 1st of October and the 8th of october), we got 136 of the document (where the age is known) where authors are between 18 and 24 years old.
To retrieve this result, we can use age histogram:
curl -L -X GET 'https://api.talkwalker.com/api/v1/search/p/<project_id>/histogram/age?access_token=<access_token>&q=published:>1633039200000 AND published:<1633644000000'
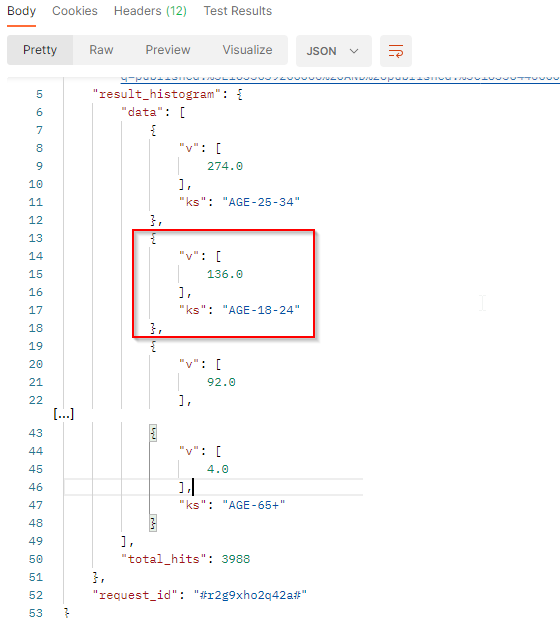
In our sample :
vis the number of documents that match the filter criteria and the age. Here we have 136 documents where the authors are between 18 and 24 years old.ksis the age group.total_hits: Total number of documents match the filter criteria.
Top countries
This diagram shows the repartition of source sites for all documents which match the project criterias within the filtered period by country:
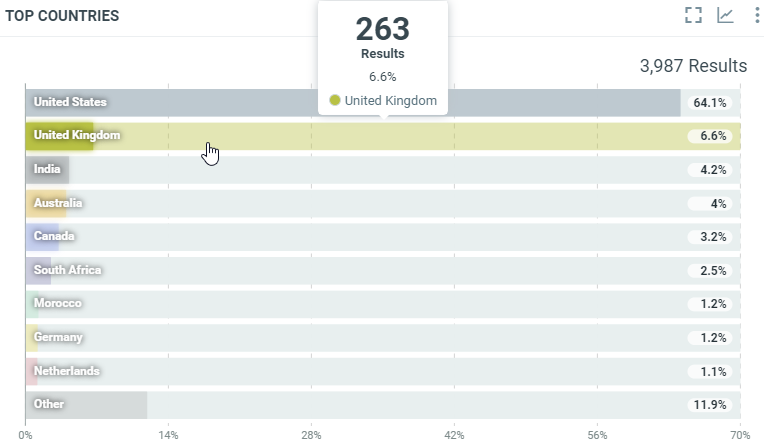
In this sample, over the filtered period (between the 1st of October and the 8th of october), we got 263 documents published on a site located in UK.
To retrieve this result, we can use country histogram:
curl -L -X GET 'https://api.talkwalker.com/api/v1/search/p/<project_id>/histogram/country?access_token=<access_token>&q=published:>1633039200000 AND published:<1633644000000'

In our sample :
vis the number of documents that match the filter criteria and the country. Here we have 263 documents published on a site located in the UK.ksis the country code (ISO 2 letters country codes).total_hits: Total number of documents match the filter criteria.
Top languages
This diagram shows the repartition of the languages used in all documents which match the project criterias within the filtered period:
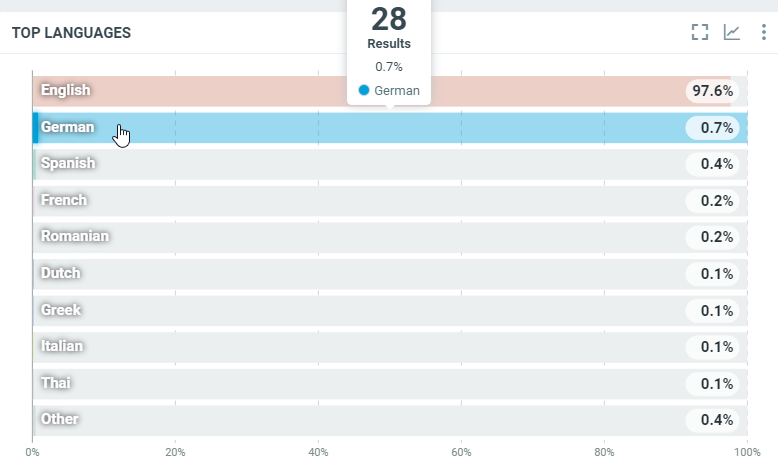
In this sample, over the filtered period (between the 1st of October and the 8th of october), we got 28 documents written in German.
By default, if the language is not detected on the document, it will be English.
To retrieve this result, we can use language histogram:
curl -L -X GET 'https://api.talkwalker.com/api/v1/search/p/<project_id>/histogram/language?access_token=<access_token>&q=published:>1633039200000 AND published:<1633644000000'
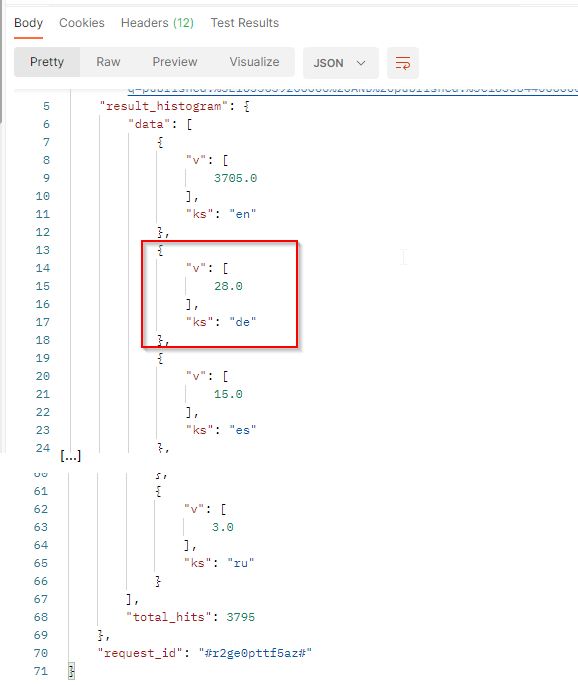
In our sample :
vis the number of documents that match the filter criteria and the country. Here we have 28 documents written in German.ksis the language code (ISO 2 letters code).total_hits: Total number of documents match the filter criteria.
Top family status
This diagram shows the repartition of the authors' family status for all documents which match the project criterias within the filtered period when it can be determined:
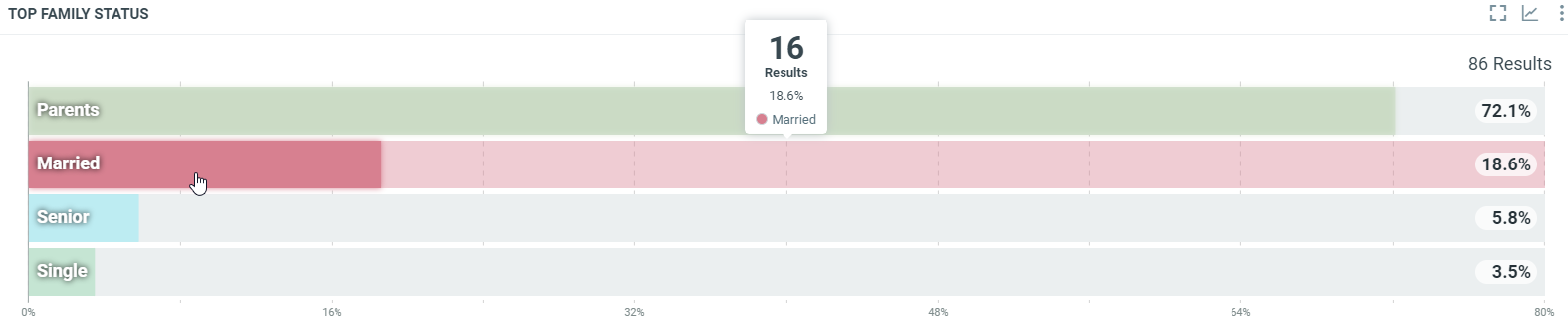
In this sample, over the filtered period (between the 1st of October and the 8th of october), we got 16 documents written by married authors.
By API, it’s not possible to get it in one call. You need to make a call for each family status.
To retrieve this result, we can use published histogram with the parameter q setted to demographic filter metric you want to retrieve. It can be one of these values: familystatus-parents, familystatus-single, familystatus-married or familystatus-senior
curl -L -X GET 'https://api.talkwalker.com/api/v1/search/p/<project_id>/histogram/published?access_token=<access_token>q=demographic:familystatus-married&interval=2w&min=1633039200000&max=1633644000000'
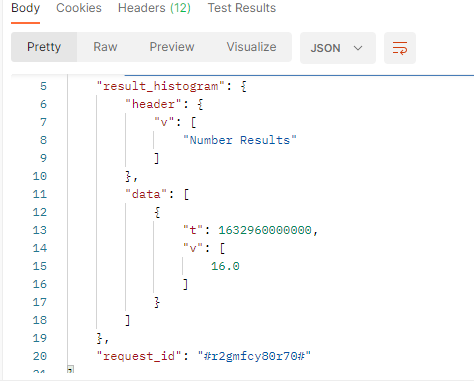
In our sample :
tis the timestamp (beginning of the period).vis the number of published documents which match the filter criterias in the filtered period and the demographic filter. we got 16 documents written by married authors (when it can be determined) in the period.
Top interests
This diagram shows the repartition of the authors' interests for all documents which match the project criterias within the filtered period when it can be determined:
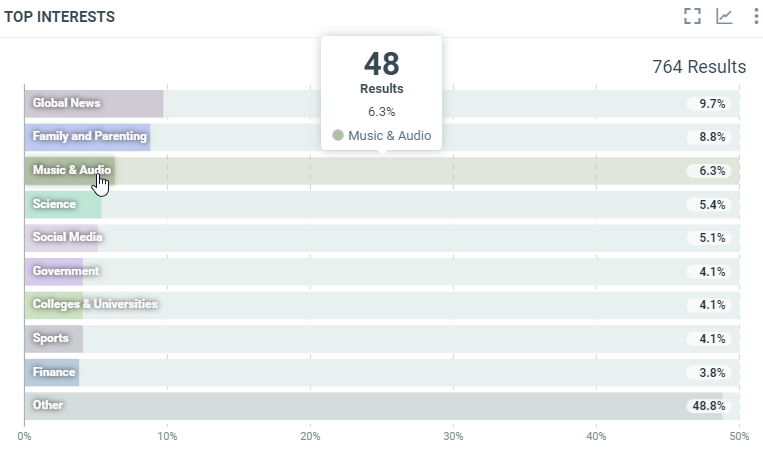
In this sample, over the filtered period (between the 1st of October and the 8th of october), we got 48 documents where authors have an interest on "Music & Audio".
To retrieve this result, we can use interest histogram:
curl -L -X GET 'https://api.talkwalker.com/api/v1/search/p/<project_id>/histogram/interest?access_token=<access_token>&q=published:>1633039200000 AND published:<1633644000000'
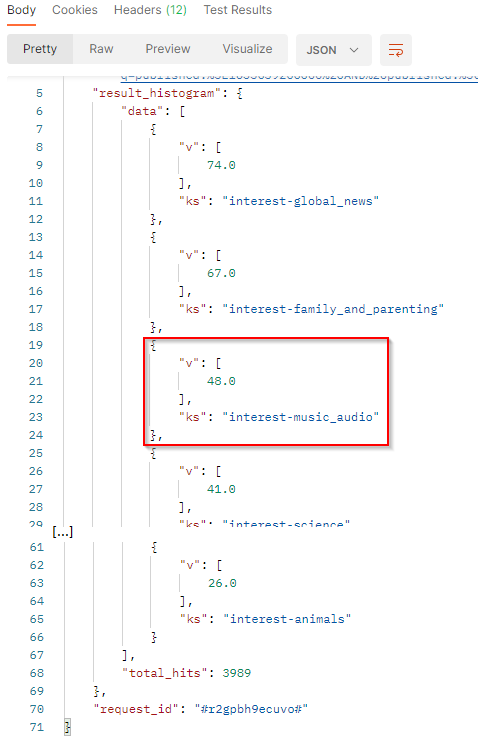
In our sample :
vis the number of documents that match the filter criteria and the interest code. Here we have 48 documents where the authors are interested in music & audio (when it can be determined).ksis the interest code.total_hits: Total number of documents match the filter criteria.
Top occupations
This diagram shows the repartition of the authors' occupations for all documents which match the project criterias within the filtered period when it can be determined:
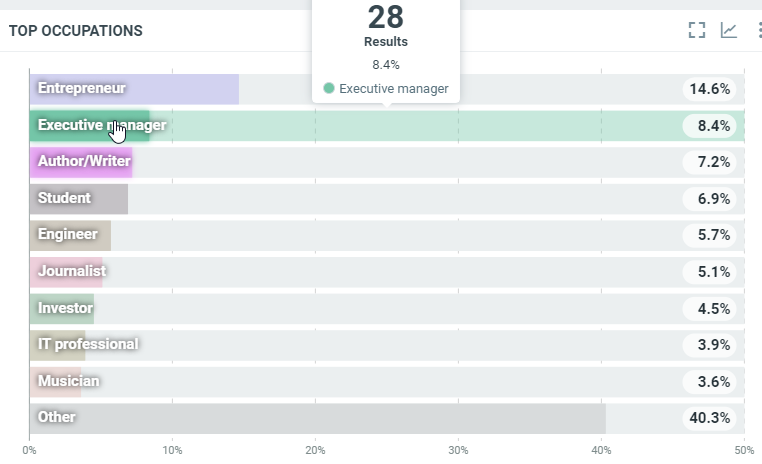
In this sample, over the filtered period (between the 1st of October and the 8th of october), we got 28 documents where authors were identified as "Executive manager".
To retrieve this result, we can use occupation histogram:
curl -L -X GET 'https://api.talkwalker.com/api/v1/search/p/<project_id>/histogram/occupation?access_token=<access_token>&q=published:>1633039200000 AND published:<1633644000000'
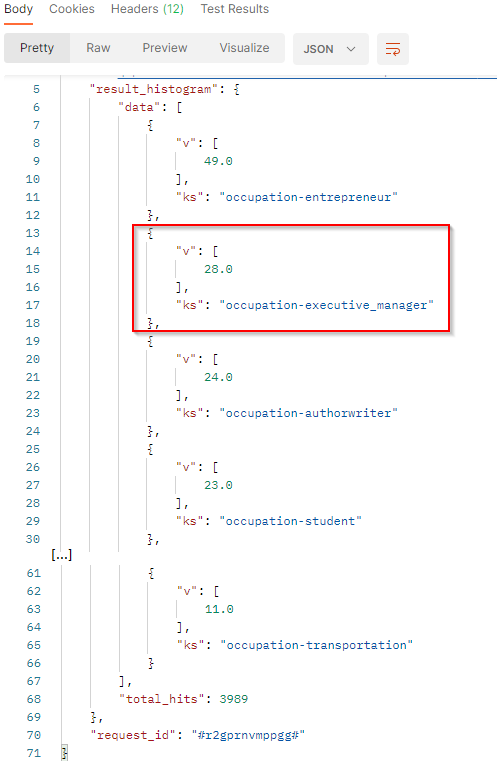
In our sample :
vis the number of documents that match the filter criteria and the occupation code. Here we have 28 documents where the authors are executive managers (when it was determined).ksis the occupation code.total_hits: Total number of documents match the filter criteria.
Share of individual/business
This diagram shows the repartition of the authors' type (individual or company) for all documents which match the project criterias within the filtered period when it can be determined:
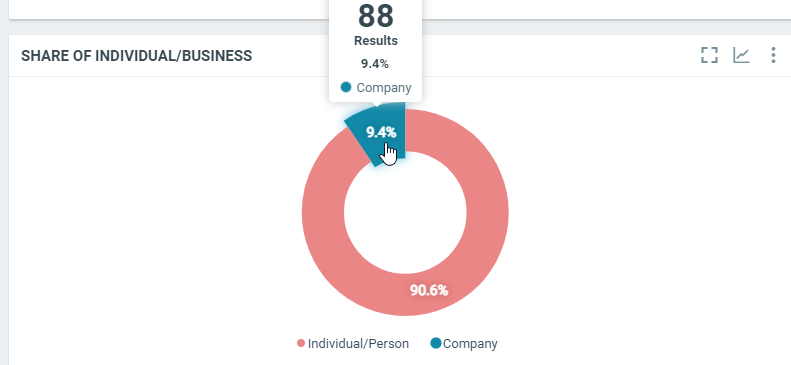
In this sample, over the filtered period (between the 1st of October and the 8th of october), we got 88 documents from authors where the type was identified as "company".
To retrieve this result, we can use published histogram with the parameter q setted to author's type you want to retrieve. It can be one of these values: individual, business.
curl -L -X GET 'https://api.talkwalker.com/api/v1/search/p/<project_id>/histogram/published?access_token=<access_token>&q=authorcategory:business&interval=2w&min=1633039200000&max=1633644000000'
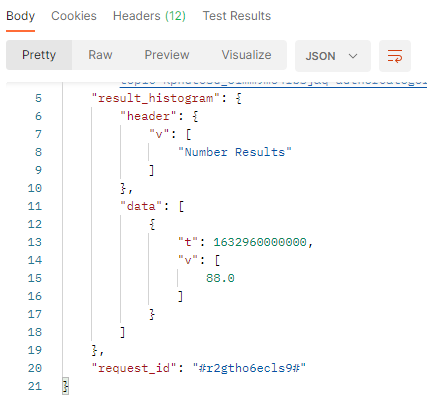
In our sample :
tis the timestamp (beginning of the period).vis the number of published documents which match the filter criterias in the filtered period and the autjorcategory filter. we got 88 documents written by authors identified as company.
Share of automated accounts
This diagram shows the number of documents which match the project criterias within the filtered period and when the post is identified as posted from an automatic account.
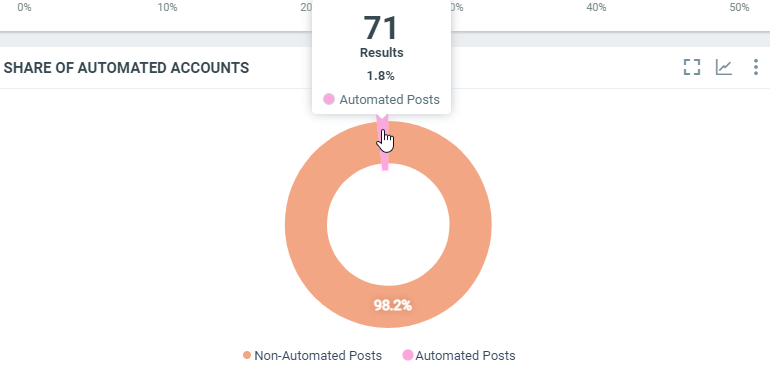
In this sample, over the filtered period (between the 1st of October and the 8th of october), we got 71 documents from "automated" accounts.
To retrieve this result, we can use published histogram with the parameter q setted with the tag is:automated_post or not.
curl -L -X GET 'https://api.talkwalker.com/api/v1/search/p/<project_id>/histogram/published?access_token=<access_token>&q=is:automated_post&interval=2w&min=1633039200000&max=1633644000000'
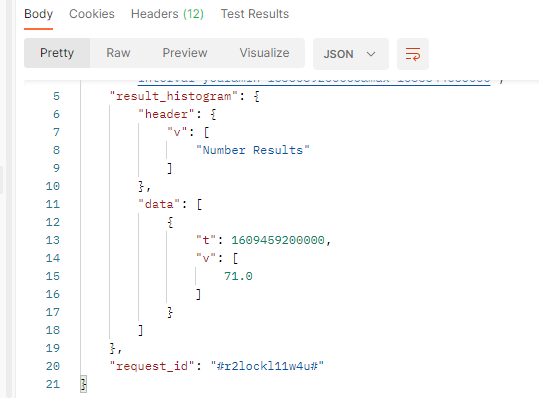
In our sample :
tis the timestamp (beginning of the period).vis the number of published documents which match the filter criterias in the filtered period and the tag. we got 71 documents tagged as an automated post.