How to monitor your Talkwalker’s project
Use-case description
You want to display in real time new mentions and articles indexed in your project in Talkwalker. In this use-case, your system is waiting for articles and mentions pushed by Talkwalker so that it can be directly displayed.
It is possible to monitor only on a subset of topics/filters defined in your project settings.
Listen to the project
General use-case
To monitor a project, no need to specify a stream ID, just open the stream on the project:
curl -X GET 'https://api.talkwalker.com/api/v3/stream/p/<project_id>/results?access_token=<access_token>'
To limit the monitoring to specific topics and/or filters, you can add the additional parameters topic with the topic or filter ID (filters will be applied to all rules and topics):
curl -X GET 'https://api.talkwalker.com/api/v3/stream/p/<project_id>/results?&topic=<topic ID 1>&topic=<topic ID 2>&topic=<filter ID 1>&access_token=<access_token>'
In this sample, documents which match filter ID 1 AND (topic ID 1 OR topic ID 2) will be pushed.
To know to which topic and filter the article match, you can retrieve the ID in the field matched_profile:
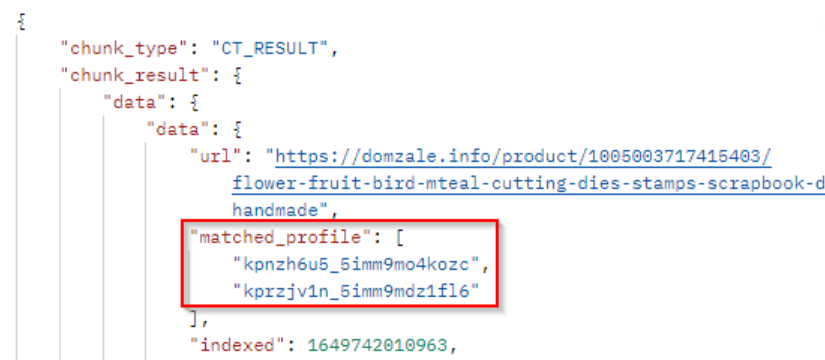
Additional keywords or filter to monitor in your project
You can add an additional set of keywords or filter rules when you monitor your project. Just add an additional q parameter to your call:
curl -X GET 'https://api.talkwalker.com/api/v3/stream/p/<project_id>/results?q=<rule_1>&access_token=<access_token>'
In this sample, only the documents which are indexed in your project AND match the rule_1 will be pushed to the stream.
Control your credits or test a stream
If you want to limit the number of results in the transaction:
- To control the number of credits consumed by your stream.
- To test the outcome of your stream during your tests.
You can add an additional parameter max_hits to control the number of results.
curl -X GET 'https://api.talkwalker.com/api/v3/stream/p/<project_id>/results?max_hits=<number of results>&access_token=<access_token>'
Once you reach the number of results, the transactions will end. New articles or mentonned will not be pushed anymore to the stream.
If I want to avoid any loss of data
Persisted data
If it’s more important to not lose any article or mention you monitor, then you can send them into a collector (it will act like a queue) and listen to the collector like a stream.
The main difference is that once the collector is created and active, all new articles and mentions will be pushed to the collector (and consume credits) even if you are not listening to the collector. The data will remain accessible in the collector for 7 days.
Create/update a collector on a project
You can specify multiple streams which will be pushed to the collector.
You can add additional keywords to monitor in the collector.
curl -X PUT 'https://api.talkwalker.com/api/v3/stream/c/<collector_id>?access_token=<access_token>' \
--header 'Content-Type: application/json' \
--data-raw '{
"collector_query": {
"queries": [
{
"id": "rule_1",
"query": "cats AND dogs"
}
],
"project_topics": {
"project": "1234-abcd-1234",
"topics": [
"kpnutesu_1234abcd"
]
},
"filters": [
"kprzjv1n_1234abcd"
]
}
}'
In this sample, all documents which match the Project_ID AND topic_ID AND the filter_ID AND the collector rule_1 will be pushed in the collector.
If the collector ID already exists, the request will override the rules.
Read the collector.
Please refer to the section How to read the collector.