Introduction
Presentation of the streaming concept
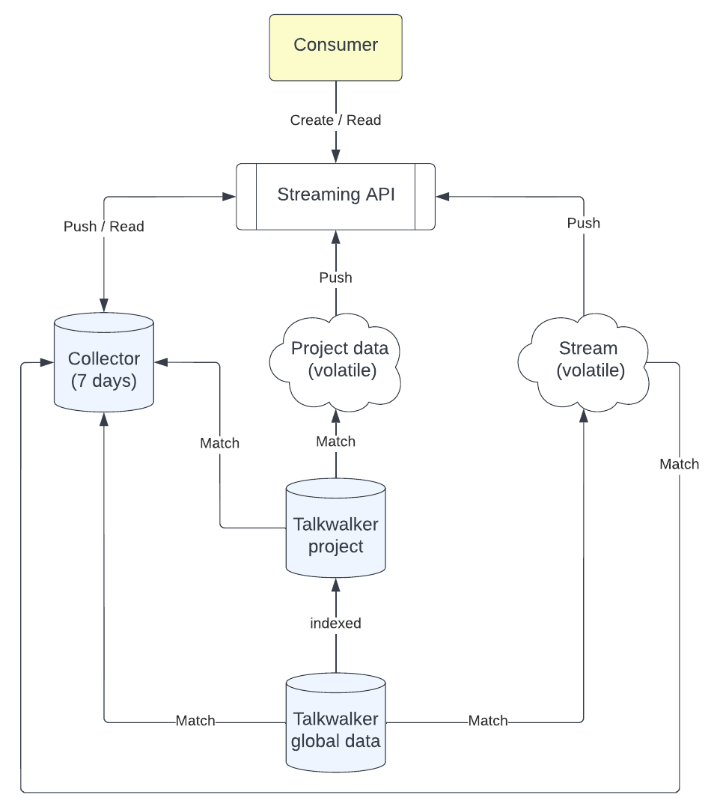
The streaming API allows you to be informed in real-time about new articles or mentions which are indexed in Talkwalker and which match predefined rules or query filters. By the way, this is an asynchronous API call where you don’t have to pull data, Talkwalker will push them through the stream.
- Updates made by an agent on the document (sentiment change, tagging, ...) will not be transmitted to the streaming API.
- Automatic tags applied by rules are also not present.
With Talkwalker API, you have 3 ways to build a stream:
- A stream on the articles and mentions which are not indexed inside your project (in this case, no social media content will be pushed).
- A stream on your project data.
- A collector which will keep track of articles and mentions you monitored for 7 days (both non indexed and project data).
Streaming process
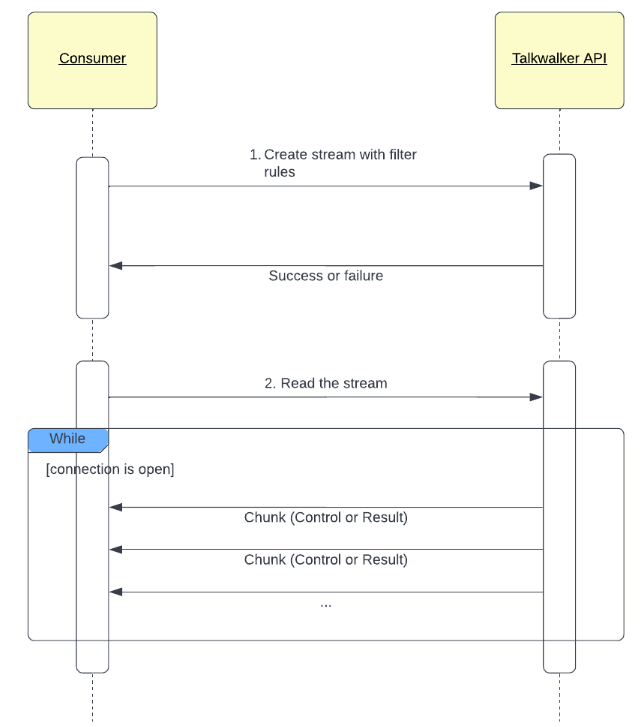
- Create a stream with filter rules you are interested in. The endpoint depends on the method you choose to create the stream (stream, project monitoring or collector).
- You start to read and listen to the stream. When a document is indexed in Talkwalker, if it matches your stream filter criterias, then the document will be pushed in a RESULT chunk.
Once you start to read the stream, the connection will remain open and the consumer will listen to events (chunks here). The consumer controls the connection and decides when it is closed:
Volatile data vs persisted data
By nature, with the stream, data is volatile. If the consumer is not listening when new documents are indexed, it will be “lost” as they are pushed on the fly. This use-case corresponds to a monitoring system which displays live data.
For persisted data, you can use a collector which acts like a queue where pushed documents (from a stream, project or a query) will remain accessible for 7 days. After these 7 days, the collector is still accessible, but documents will be removed. Once the collector is created and active, new articles are automatically pushed inside the collector, even if you are not reading it. This use-case is perfect when you want to have data in real-time (or near real-time) without any loss.